# Routing Nodes
# Node: Subflow
A subflow is a section of the flow that is defined using Subflow In and Subflow Out node. A subflow helps in better reusability of a logic and provides better readability of your code.
Subflow node invokes a subflow from any point in your flow. The node will show the list of Subflow In node names that you can select to invoke. The moment a Subflow In node is added to the canvas the Subflow node will have its name listed in its drop down.
Each subflow execution has its own context. For more information refer the Context section. Payload, variables or any other message properties are not modified by this node.
TIP
The node is available only from 2.1.4 version of Kumologica Designer. This node is recommended over using Subflow option provided by the Processor node.
# Node: Subflow In
In order to implement a subflow you need to have a Subflow In node. A Subflow In node is the starting point when defining any subflow. It is the best practice to name your Subflow In node with a proper naming so that it would easier to identify and select the flow in the Subflow node.
Payload, variables or any other message properties are not modified by this node.
TIP
The node is available only from 2.1.4 version of Kumologica Designer. This node is recommended over using Subflow option provided by the Processor node.
# Node: Subflow Out
Every subflow ends with a Subflow Out node. It is mandatory that all the subflows must be closed its execution with a Subflow Out node. The node relays the control back to the Subflow node in order to continue with the execution of the parent flow.
Payload, variables or any other message properties are not modified by this node.
TIP
The node is available only from 2.1.4 version of Kumologica Designer. This node is recommended over using Subflow option provided by the Processor node.
# Node: ForEach
ForEach node can be used for looping an array of records. The node expects an array object as its input. The output of the ForEach node will be individual records from the array and this will be available under payload object. This can be accessed using msg.payload expression.
Each loop iteration will be waiting for the previous iteration to complete. This means execution will be comparatively slower when compared to async execution achieved by Split/Join nodes. This iteration mode is specifically used for those services that are focussed on sequence of record processing. A strict sequence is maintained when the ForEach node is executed.
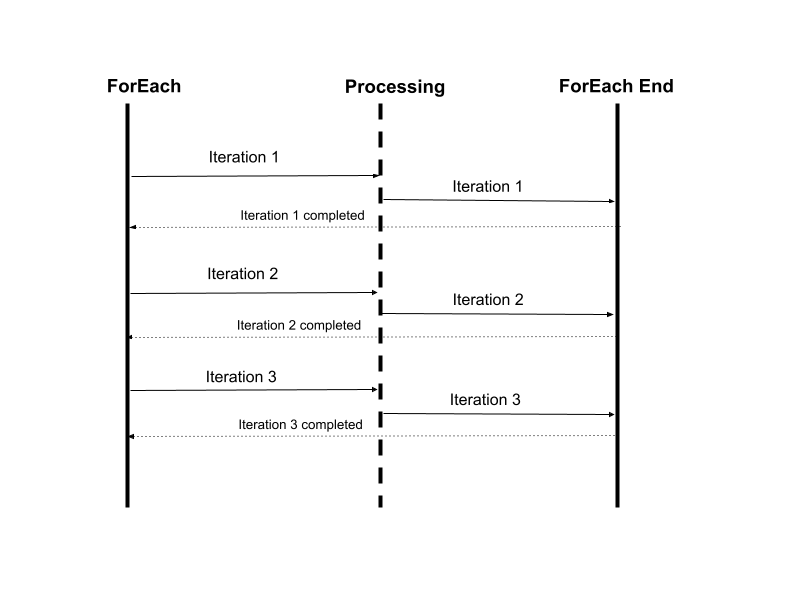
TIP
If maintaining order is not crucial, consider utilizing the Split/Join nodes for faster and asynchronous executions
# Example
# Node: ForEachEnd
ForEachEnd node ensures the completion of each iteration. All the logic for processing each individual record must be implemented by placing the appropriate nodes between ForEach node and ForEachEnd node.
TIP
The node is available only from 2.1.4 version of Kumologica Designer. This node is recommended over using the looping option provided by the Processor node.
# Node: ForEachBreak
ForEachBreak terminates execution of ForEach sequence and transfers processing to the completion of ForEachEnd node. The message processing is routed to the next node after ForEachEnd.
# Node: Processor
WARNING
This node is deprecated. For subflow and looping implementation we strongly recommend to use Subflow node and ForEach node respectively.
Processor nodes brings easy to use loops and OOP (object oriented programming) features to the flow programming paradigm. Three nodes allow you to create extensible, scoped, looped, and prioritized flows. You can organize flows for readability and create extendable design patterns.
Processor provides following key features:
- Late binding - extend complex flows without modifying the original flow
- Looping - call flow segments repeatedly with conditional iteration
- Prioritize flows - allow for execution of subflows based on priority number.
The processor node works like a subflow, allowing you to define a reusable flow segment between the node's processor in and processor out.
Processor node invokes the processor in node by a prefix naming schema; allowing for multiple add-on flow segments to be appended to the original flow. Processor node's name determines the name of the corresponding processor in node that will be activated. Use the processor node's name as a prefix for all subsequent processor in nodes that you wish to be callable by the processor node. For instance, an processor node named "Sample", will call any processor in nodes with names like "Sample in", "Sample-in", "Sample_Exercise", or "sample.acme.com".
# Subflow Context
Subflow context is the context defined when the flow is having a processor node with subflow operation selected. This context starts from the processor in node to processor out node. The variables defined in the sub flow will be visible across all the nodes in the sub flow but will not be visible on the main flow context or on any other subflow context. Environment variables and message object will be visible across all the nodes placed on a subflow.
# Example
# Node: Split
Split node splits the message into a single message into a sequence of messages.
The exact behavior of the node depends on the type of msg.payload.
If the message type is String\Buffer then the message is split using the specified character (default: \n), buffer sequence or into fixed lengths.
If the message type is an Array then the message is split into either individual array elements, or arrays of a fixed-length.
If the message type is an Object then the message is split and sent for each key/value pair of the object.
# Example
How to use Split node using fixed length option
How to use Split node using the String\Buffer option
How to use Split node using Object key value pair
# Node: Join
Join node turns a sequence of messages into a single message.
WARNING
2.1.3 version and above of Kumologica designer doesn't support the 3 modes of operation (Automatic, manual and reduce) provided by the Join node.
For those users who are using designer version 2.1.2 and below the node has three modes of operation.
Automatic- Attempts to reverse the action of a previous split node.Manual- Allows finer control on how the incoming message sequence should be joined.Reduce- Allows a JSONata expression to be run against each message in the sequence and the result accumulated to produce a single message.
# Node: Switch
The Switch node allows messages to be routed to different branches of a flow by evaluating a set of rules against each message.
The node will route the message to the first matching rule.
# Properties
Property: Rules are evaluated against the value of this field. It supports dynamic expressions.Rules- Dynamic list of rules to compare against the property.equals- true iff property === valuenot equals- true iff property !== valueless than- true iff property < valueat most- true iff property <= valuegreater than- true iff property > valueat least- true iff property >= valueis between- true iff property >= value1 && property <= value2contains- true iff _property contains substring valueregex- true iff _property matches the regular expression valueis true- true iff property is TRUEis false- true iff property is FALSEis nil- true iff property is null or undefinedis not nil- true iff property is not null nor undefinedis of type- true iff property is of the type valueis empty- true iff strings, arrays or buffers are of length 0, or if object is not null and it does not have any keys.is not empty- true iff strings, arrays or buffers are of length more than 0, or if object is not null and it has at least one key.otherwise- true if rest of rules were evaluated to false.
WARNING
The otherwise rule is optional, but if present ensure that it is placed at the end of the list of rules.
# Example
# Node: Scatter
Scatter node send the copy of the message to multiple subsequent nodes in parallel.The node can be used for achieving the broadcast pattern. Failure in any of the route originated from the scatter node must be handled using a catch node. Unhandled exception will wait for the instance to timeout.
Payload or variable are not overwritten by the response from this node.
# Node: Gather
Gather node is always used in combination with Scatter node. All the routes initiated from the scatter node joins at Gather node. Gather node aggregates the message processed from each route into a single message before sending to the subsequent node. Failure in any of the route originated from the scatter node must be handled using a catch node. Unhandled exception will wait for the instance to timeout.
Payload is overwritten by the response from this node.
# Node: Sort
Sort node can be used to sort the sequence of an array of objects based on a key.
# Properties
Property- Payload or variable having the array object to be sorted.Sort key- Key element available in the array object based on which sorting to be done.Order- Supports ascending order and descending order of sorting. Default is ascending order.
Payload or variable is overwritten by the response from this node.